主题
LLM节点
LLM 是构建 AI 应用的核心。我们相信,大型语言模型(LLM)将改变软件的使用方式和我们的工作方式。有了 BetterYeah AI,使用 LLM 变得非常简单。 与 LLM 的通信是通过自然语言和书面形式进行的。用于向 LLM 提供信息和指令的文本称为 "提示(Prompt)"。 每次使用 LLM 时,您只需要:写好提示和选择合适的模型。
如何使用
- 点击 「+」按钮,选择 LLM 节点;
- 配置节点内容。
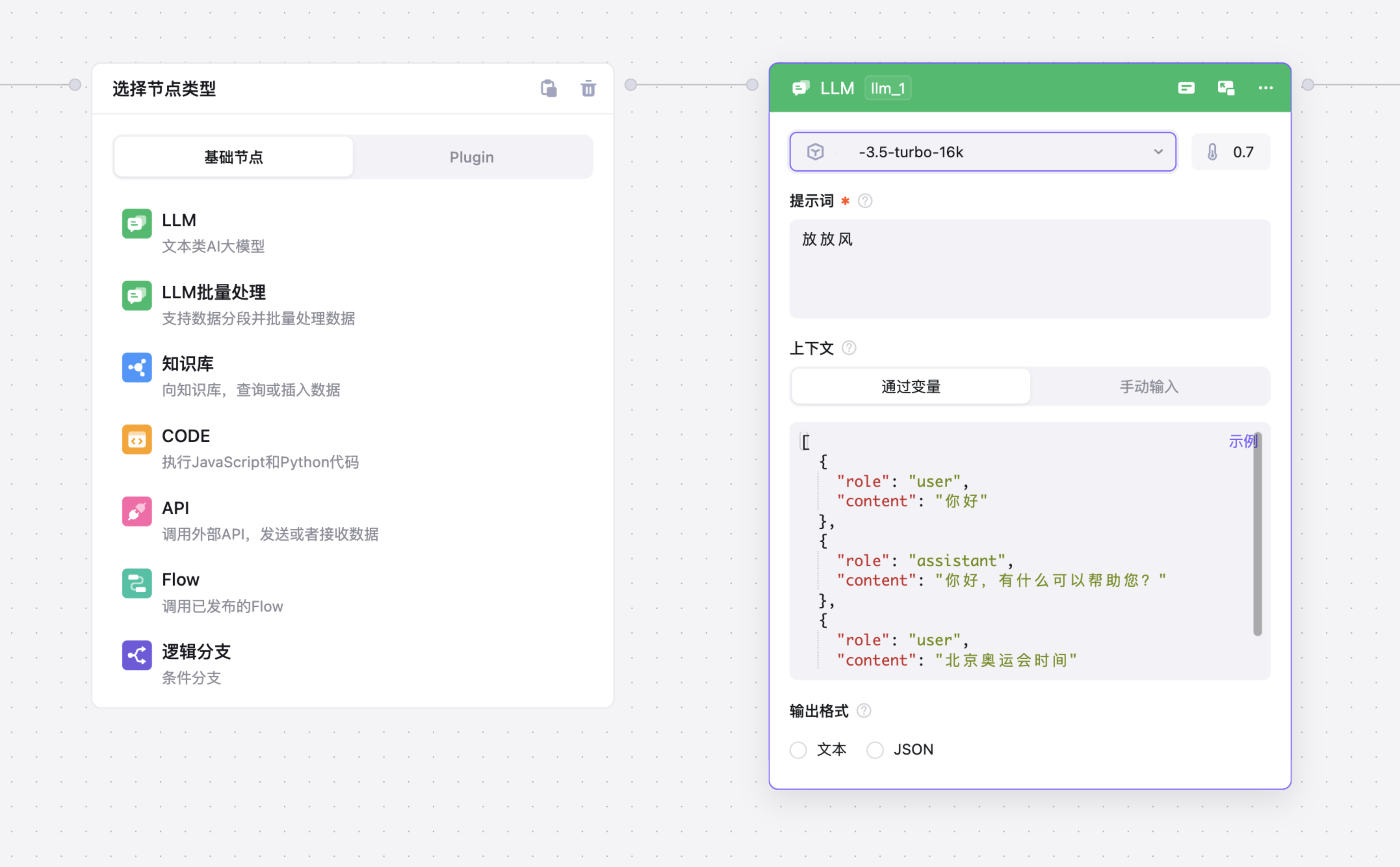
配置
模型
我提供市面上几乎所有的主流 LLM模型,你可以根据你的需求,选择合适的模型。
| 模型分类 | 供应商 | 名称 |
|---|---|---|
| ChatGLM3 | ChatGLM3 | ChatGLM3-6B |
| ChatGLM3 | ChatGLM3 | ChatGLM3-6B-32K |
| ChatGLM3 | ChatGLM3 | ChatGLM3-6B-Base |
| Moonshot 系列模型 | Moonshot | moonshot-v1-8k |
| Moonshot 系列模型 | Moonshot | moonshot-v1-32k |
| Moonshot 系列模型 | Moonshot | moonshot-v1-128k |
| 百度千帆大模型 | 百度 | BLOOMZ-7B |
| 百度千帆大模型 | 百度 | ERNIE-Bot |
| 百度千帆大模型 | 百度 | ERNIE-Bot-4 |
| 百度千帆大模型 | 百度 | AquilaChat-7B |
| 百度千帆大模型 | 百度 | ChatGLM2-6B-32K |
| 百度千帆大模型 | 百度 | ERNIE-Bot-turbo |
| 百度千帆大模型 | 百度 | Llama-2-7b-chat |
| 百度千帆大模型 | 百度 | Llama-2-70b-chat |
| 百度千帆大模型 | 百度 | Qianfan-Chinese-Llama-2-7B |
| 智谱 ChatGLM 系列模型 | 智谱 | GLM-4 |
| 智谱 ChatGLM 系列模型 | 智谱 | GLM-3-Turbo |
| 智谱 ChatGLM 系列模型 | 智谱 | chatglm_pro |
| 智谱 ChatGLM 系列模型 | 智谱 | chatglm_std |
| 智谱 ChatGLM 系列模型 | 智谱 | chatglm_lite |
| 智谱 ChatGLM 系列模型 | 智谱 | chatglm_lite_32k |
| 讯飞星火认知大模型 | 讯飞 | general |
| 讯飞星火认知大模型 | 讯飞 | generalv2 |
| 腾讯混元大模型 | 腾讯 | HuanYuan |
| 阿里通义千问系列模型 | 阿里 | qwen-plus |
| 阿里通义千问系列模型 | 阿里 | qwen-turbo |
创造性
当配置的创造性值较大时,模型输出的概率分布更平均,这意味着您将获得更多样化的回答。
当配置的创造性值较大时,模型输出的概率分布更平均,这意味着您将获得更多样化的回答。
提示词
提示词是一种书面文字,其中包括您要提供给语言模型的信息以及指令和期望。清晰明确的提示词,是完成需求的关键。有关提示语工程的说明和最佳实践,可以参阅提示工程指南。也可以在全屏调试中,使用我们的优化建议。文本框中可以使用语法 引入其他节点的输出或变量例如,获取start节点的content值,可以使用 start.content 将其包含在提示词中。
更详细的变量使用指南可以使用参考 Flow中的变量和数据流转。
上下文
可创建或读取上下文故事线,让AI更准确的理解意图并处理
- 通过变量: 你可以使用 JSON格式来传递上下文:
json
[
{
"role": "user",
"content": "你好"
},
{
"role": "assistant",
"content": "你好,有什么可以帮助您?"
},
{
"role": "user",
"content": "北京奥运会时间"
}
]手动输入 在文本框中输入上下文
输出格式(OpenAI 模型)
文本:直接输出文本
JSON:输出 JSON 文本,更加结构化,易于与其他模块连接。
多模态使用
多模态模型与文本类模型,在使用上有区别,多模态模型需要将图片、视频等信息,作为上下文传递给LLM节点处理,步骤如下:
1、选择带有多模态标识的模型(每个模型支持的能力会标记在后面) 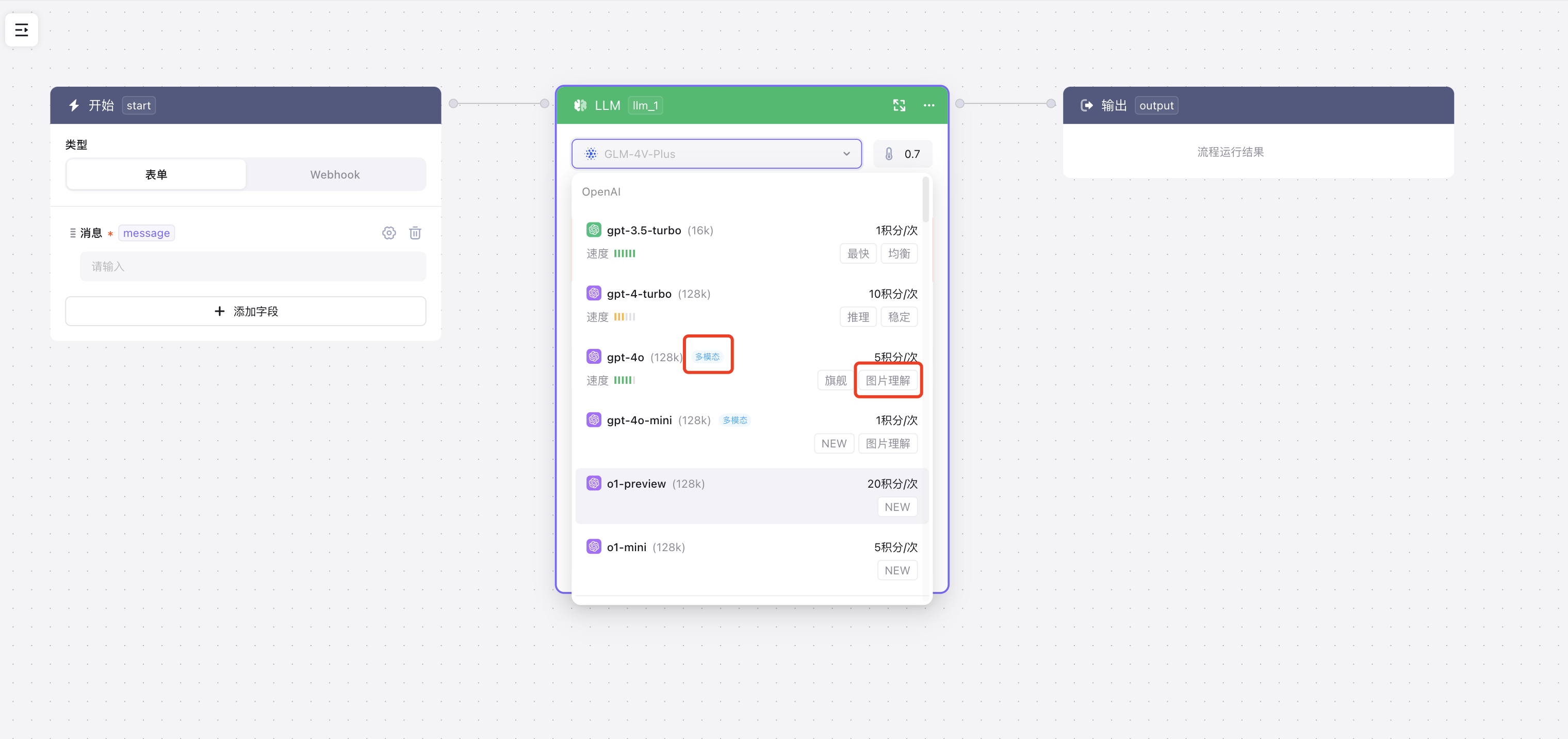 2、根据不同的模型,需要在上下文中输入不同的Json:
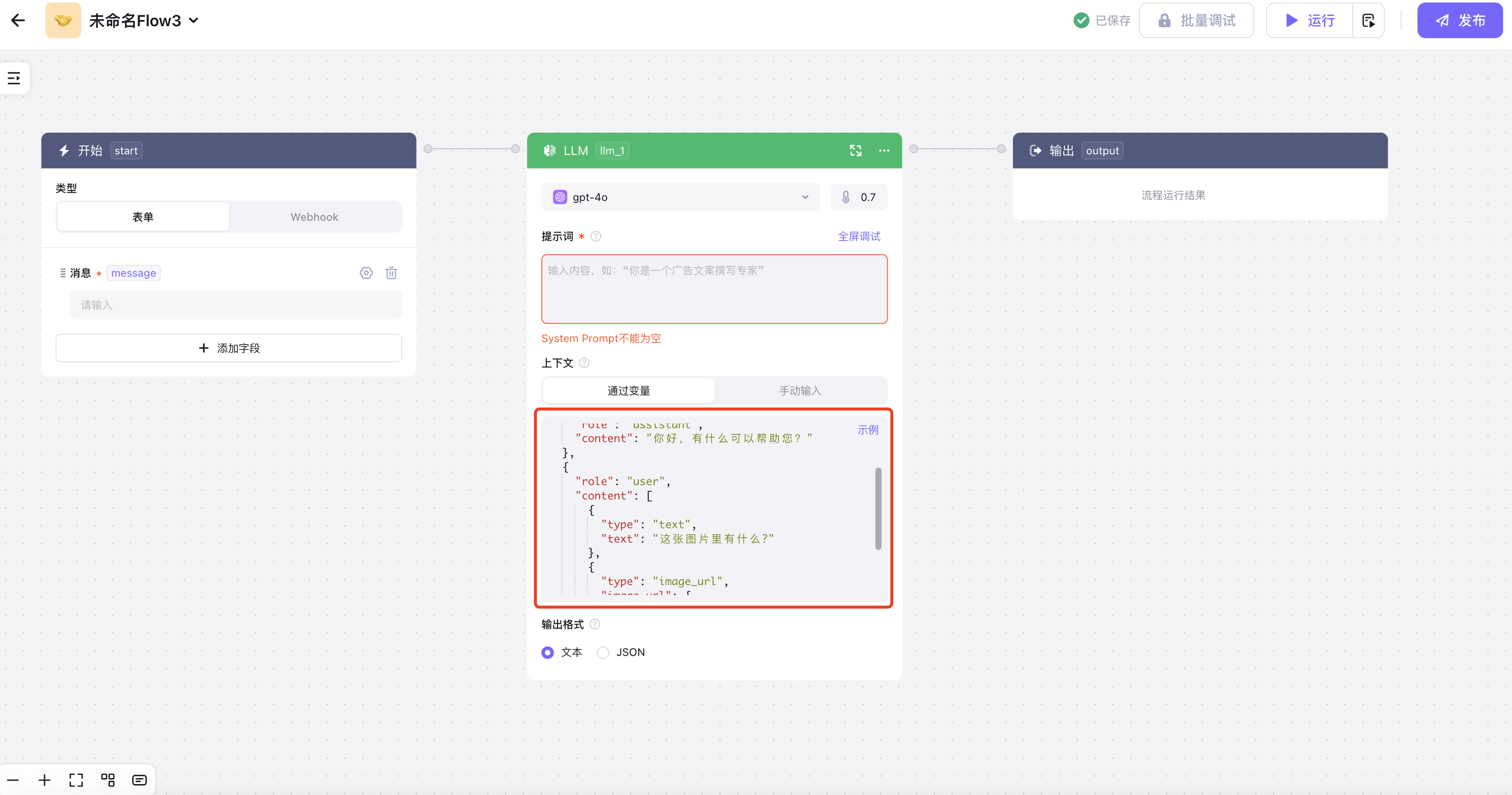
2、根据不同的模型,需要在上下文中输入不同的Json:
2.1、图片类多模型可以参考如下示例,输入在上下文中:
json
[
{
"role": "user",
"content": "你好"
},
{
"role": "assistant",
"content": "你好,有什么可以帮助您?"
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "这张图片里有什么?"
},
{
"type": "image_url",
"image_url": {
"url": "https://xxxx/walk.jpg"
}
}
]
}
] 2.2、视频类多模型可以参考如下示例,输入在上下文中:
2.2、视频类多模型可以参考如下示例,输入在上下文中:
json
[
{
"role": "user",
"content": "你好"
},
{
"role": "assistant",
"content": "你好,有什么可以帮助您?"
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "视频主要展示了什么?"
},
{
"type": "video_url",
"video_url": {
"url": "https://xxxx/walk.mp4"
}
}
]
}
] 3、最后,再向 LLM 输入prompt指令,即可使用模型的多模态处理能力。
3、最后,再向 LLM 输入prompt指令,即可使用模型的多模态处理能力。